Pronounce, proven efficiency
Results speak.




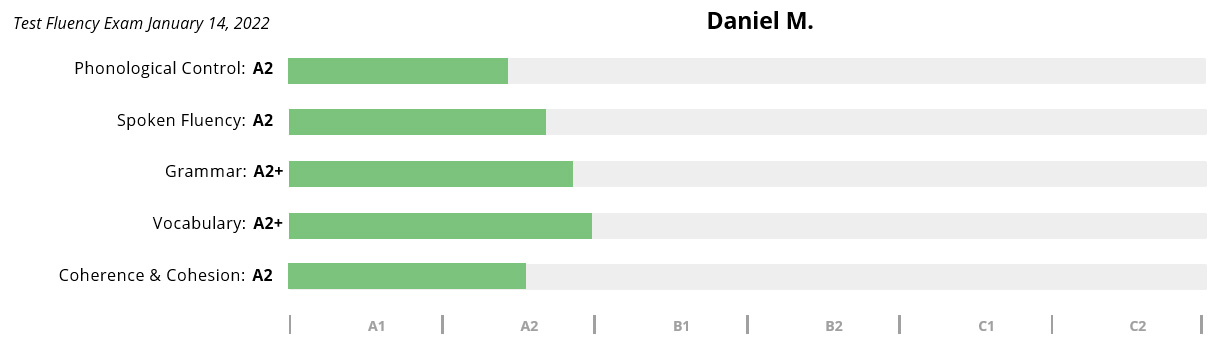
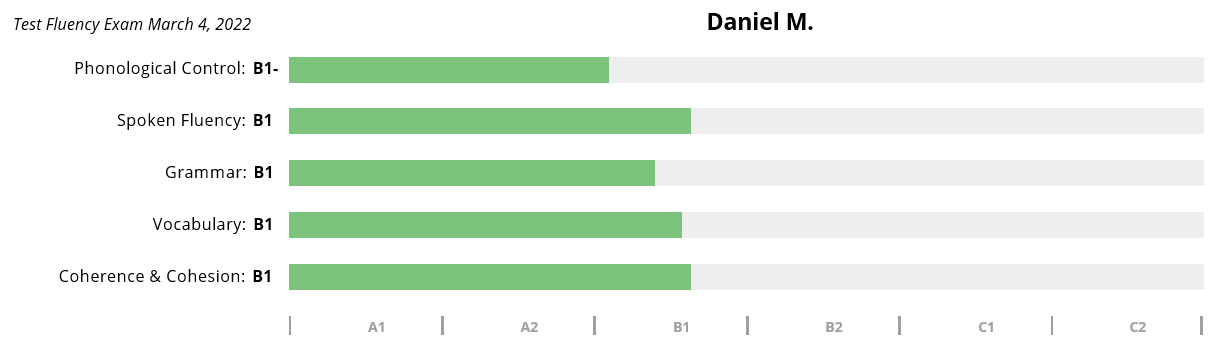
Daniel M
Project Manager

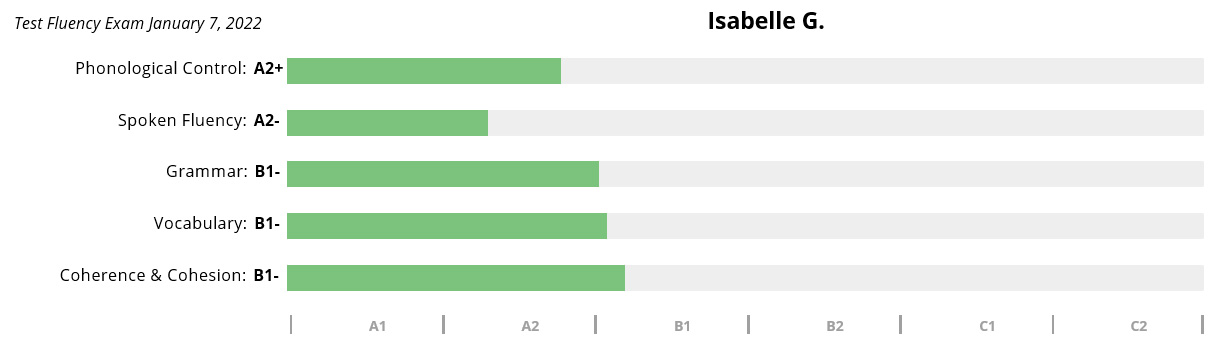
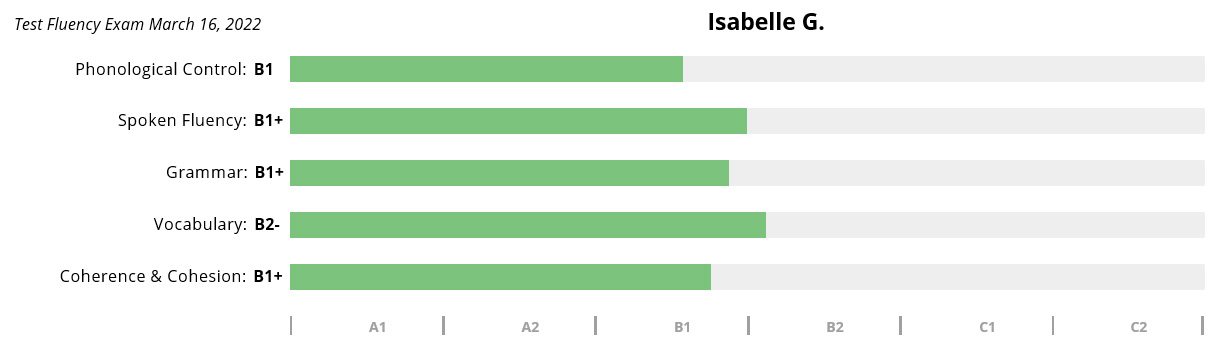

Isabelle G.
Actively seeking employment

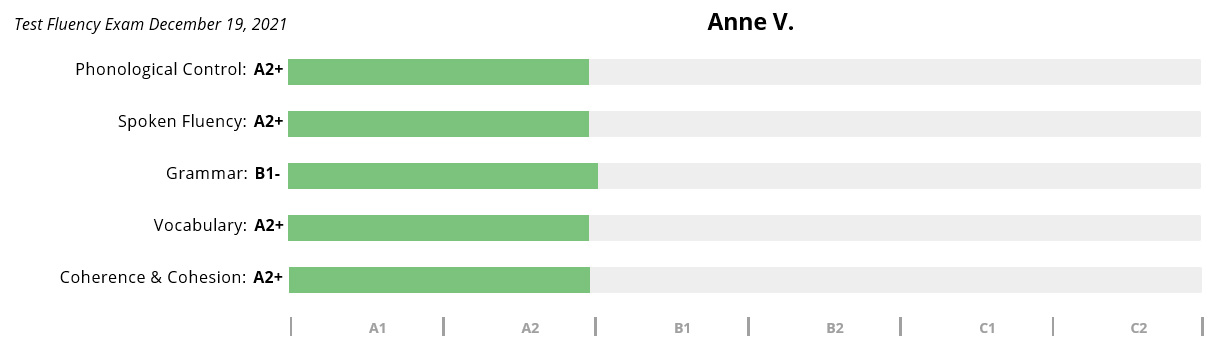
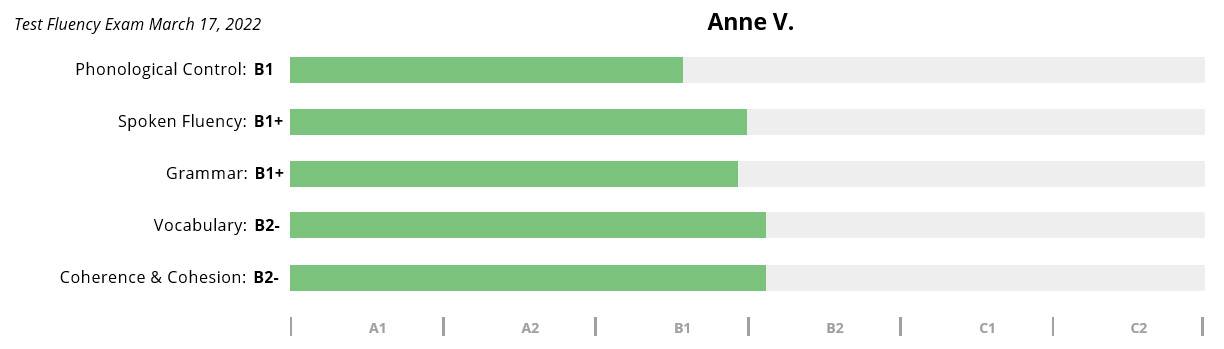
Anne V
Chargée d'affaires

Samuel, 42 ans
Evolution : B1+ à B2 (20h)
Samuel, 42 ans
Evolution : B1+ à B2 (20h)
Samuel, 42 ans
Evolution : B1+ à B2 (20h)
Samuel, 42 ans
Evolution : B1+ à B2 (20h)
Samuel, 42 ans
Evolution : B1+ à B2 (20h)
Samuel, 42 ans
Evolution : B1+ à B2 (20h)

